
tl;dr: ubuntu 22.04 jammy jellyfish needs vxlan capability to support microk8s.
# after installing ubuntu 22.04 jammy jellyfish (or upgrading) run sudo apt install linux-modules-extra-5.15.0-1005-raspi linux-modules-extra-raspi
I cut my teeth typing assembly language listings out of Byte magazine; overclocking used to involve unsoldering and replacing the crystal on the motherboard; operating system distribution used to come on multiple floppies. I’ve put in my dues to earn my GreyBeard status.
I have learned two undeniable truths:
- Always favor clean OS installs vs. in-place upgrades
- Don’t change a lot of shit all at once
Every time I was logging into one of the cluster nodes, I’d see this
I’ve been kicking the “ops” can down the road but I had some free time, so let’s break rule #1 and run sudo do-release-upgrade. Ubuntu has generally been good to me (i.e. it just works), so there shouldn’t be any problems. And there wasn’t. The in-place upgrade was successful across all the nodes.
Well that was easy. Might as well break rule #2 and also upgrade microk8s to the latest/stable version (currently 1.26). My microk8s version was too old to go directly to the latest version, so no biggie I’ll just rebuild the cluster.
sudo snap remove microk8s sudo snap install microk8s --classic --channel=latest/stable microk8s add-node # copy/paste the shizzle from the add-node to the target node to join, etc.
And that is when shit when south. Damn, I broke my rules and got called on it.
Cluster dns wasn’t resolving. I was getting metrics-server timeouts. And the cluster utilization was higher than normal which I attributed to cluster sync overhead.
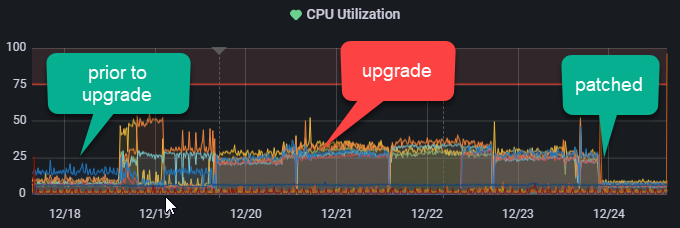
I went deep down the rabbit hole. I was focused on dns because without that, nothing would work. I used the kubernetes debugging dns resolution and tried various microk8 configurations. Everything was fine with a single node. But in a cluster configuration nothing seemed to work.
For my home network, I use pihole and I have my own dns A records for stuff on my network. So I also went down the path of reconfiguring core-dns to use /etc/resolve.conf and/or point it at my pihole instance. That was also a bust.
I also enabled metallb and this should have been my “ah ha!” On a single node, I could assign a loadbalancer ip address. But in a cluster, nope. This is all layer 2 type stuff.
Lots of google-fu, and I stumble across Portainer Namespace Issue. I was also using Portainer to troublehsoot. Portainer on a single node worked fine. But Portainer in a cluster could not enumerate the namespaces (cluster operation). But I see this post by @allardkrings:
the difference of my setup with yours is that I am running the kubernetes cluster on 3 physycal raspberry PI nodes.
I did some googling and found out that on the Raspberry PI running Ubuntu 22.04 the VXLAN module is not loaded by default.
Running
sudo apt install linux-modules-extra-5.15.0-1005-raspi linux-modules-extra-raspi
solved the problem.
That caught my eye, and clicking on the issue linked to that post made it click. I was also seeing high CPU utilization, metallb was jacked (layer 2), etc.
After installing those packages and rebuilding the microk8 cluster, everything “just works.”
